
Buzz 是一个基于 OpenAI 开源的 Whisper 语音识别模型实现的实时语音转文字工具,并且可以通过 OpenAI 的接口实现实时翻译。
因为如果直接运行 Whisper 模型还得配置 Python 环境,经常使用也很麻烦,但是 GUI 就舒适多了。
下载
这是一个开源软件,你可以在 GitHub下载 。
使用
软件的功能非常简单,可以通过电脑麦克风录制声音转为文字,或者导入音频视频文件生成逐句字幕或逐词字幕。
因为本体是一个免配置的 Whisper 模型的GUI,初次使用时,你可以选择直接使用 OpenAI 的接口或者下载 Whisper 的离线模型。
所以提示一下,AI模型的文件通常都非常巨大,同时需要的内存也非常巨大,请根据自己电脑的配置量力而行。
个人建议使用Small版本,模型尺寸较小并且速度够用。
就我个人一年多断断续续使用时的一些测试,对于中文语音识别,使用完整的large模型准确率并没有什么肉眼可见的提升。
另外,这个模型毕竟是外地模型,所以对于一些中文方言并不能分辨,对于方言识别还是选择国产的模型吧。除了方言之外,毕竟我们实际上每个人都会有一些口音,一些我们的东百普通话、荷兰普通话、广吸普通话等这些,这个模型也是不能分辨的,会直接按照普通话去识别。同时,这个模型仍然具有一些语音识别领域的“世纪难题”,一些声音嘈杂以及七嘴八舌的环境下识别率并不好。
我的使用场景一般是甲方打来电话沟通需求时候我又懒得做笔记,所以对于准确率的要求并没有那么的严格,我是经常遇到一些不知道什么行业转过来的那种神仙老板,就特别信奉各种大厂黑话,总之是主打一个虽然不懂但是感觉很厉害,还有一类更逆天的,直接就是那种可研报告里的套话整段整段念的,每次都给我听的脑壳疼,但是直接弄成文档圈重点就省事多了,毕竟人的阅读速度是听声音或者看视频时的几倍嘛。
但是如果你希望使用这个工具给电影生成字幕或者给音乐生成歌词的时候,上面说的一些局限性就体现出来了,同时这里要说的还有另一点,这个工具截取出来的时间轴并不准确,同时断句也不是很精确,所以不建议这么使用。至于其他的一些,比如播客还有批站知识区的那种口播念稿的视频,识别字幕的效果还可以。
于是,截图中是一个简单的测试,顺便说明一下功能,使用离线的Whisper模型,模型大小为small、语言为中文、不使用单字识别。十分钟的视频识别完成用时四分半钟。
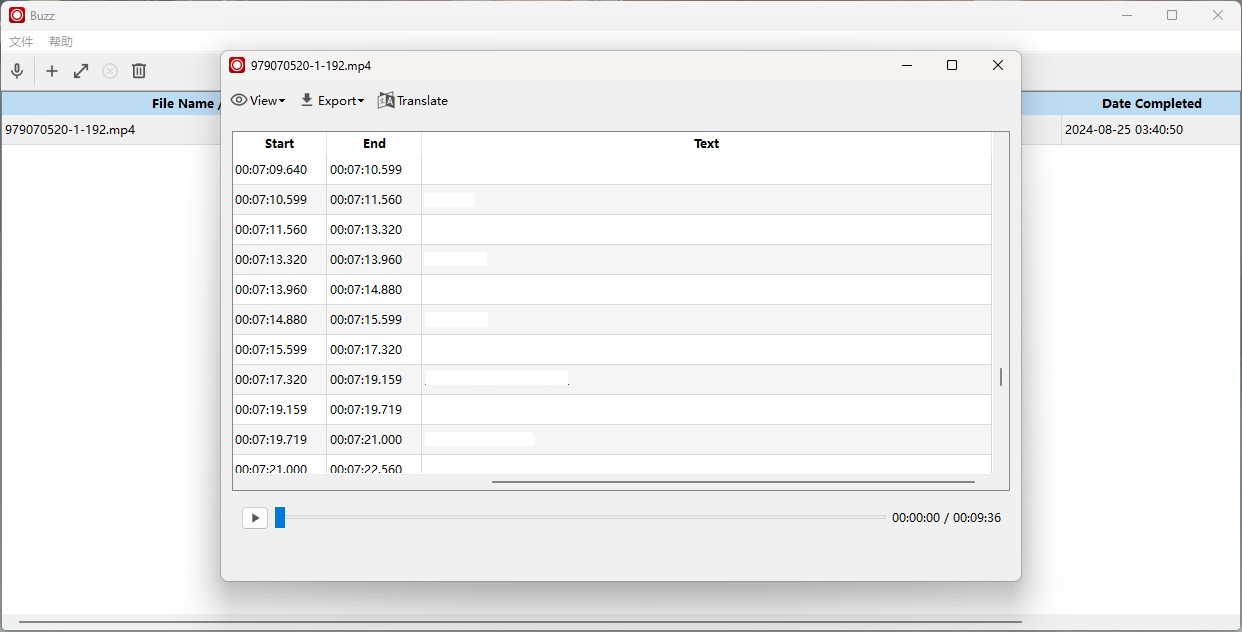
识别完成的文件双击或者点击工具栏的双箭头就可以打开识别结果,在这个界面双击可以继续编辑文字内容。
上面的几个功能按顺序是改变显示方式、导出TXT文件或者字幕文件、翻译。
使用翻译,需要在软件的 帮助->设定中添加你自己的 OpenAI API Key ,也支持配置第三方的接口镜像。
PS:因为这个软件的中文支持并不完整,很多地方都是Windows自带的i18n翻译模板,所以一些词语是比较奇怪的,如果你之前没玩过AI模型,建议就什么都不要操作,模型选择“Whisper”和“Small”直接使用就好了。
其他说明
关于 Whisper 模型各版本的文件大小和需求内存,可以在项目页面查看说明:openai/whisper
关于 Buzz 这个软件和 Whisper Desktop ,主要区别是 Buzz 是使用CPU运行的,不挑设备,而Whisper Desktop 是使用GPU运行,性能上肯定是N卡运行模型效率最高。
Buzz 在设置中并没有提供切换cuda硬件加速的选项,但是实际会不会调用显卡我也没有测试,不过Whisper原生应用(命令行方法)对于硬件加速的设置参数默认是auto,如果软件对于这项参数没有写死的话,那么应该也能调用到显卡。
另外此软件也支持直接通过 PIP 安装,包名:buzz,但是光安装这一个包是不能用的,同时得安装 ffmpeg 和 openai-whisper 。
评论区